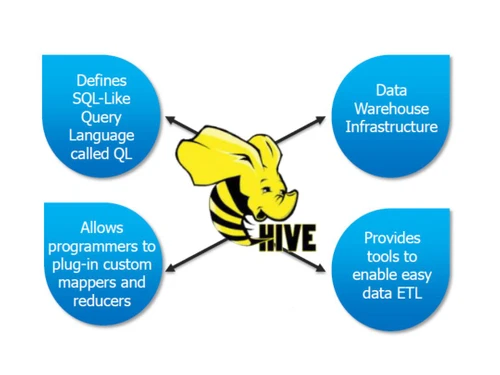
Apache Hive is an open-source tool tailored for integrating and querying extensive datasets within distributed storage systems, particularly the Hadoop Distributed File System (HDFS). Equipped with HiveQL, a SQL-like language, it simplifies the process of constructing sophisticated analytical queries for users. This functionality allows for efficient data management and analysis across vast information landscapes.
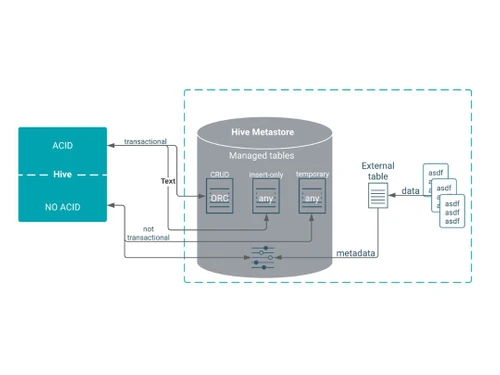
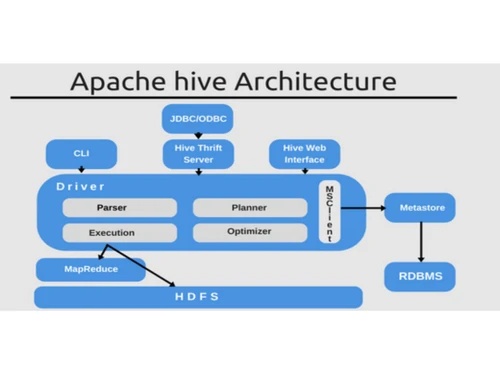
The platform converts these queries into jobs suitable for MapReduce or Apache Tez, facilitating seamless distributed processing among clusters. With its schema-on-read capability, Hive accommodates various data storage formats, enhancing flexibility. Additionally, it works in conjunction with other tools from the Apache ecosystem, such as HBase and Spark, making it a popular choice for organizations engaged in big data analytics, reporting, and summarization tasks. Details regarding pricing can be obtained through techjockey.com, and various factors influence the overall cost, including features, deployment options, and user count.