Originally created by the AMPLab at UC Berkeley and currently maintained by the Apache Software Foundation, this data processing framework excels in managing extensive datasets. Apache Spark allows developers to engage entire clusters through its programming interface, emphasizing implicit data parallelism and built-in fault tolerance. Multiple programming languages such as Java, Scala, Python, and R are supported, enhancing the development of faster, more robust applications.
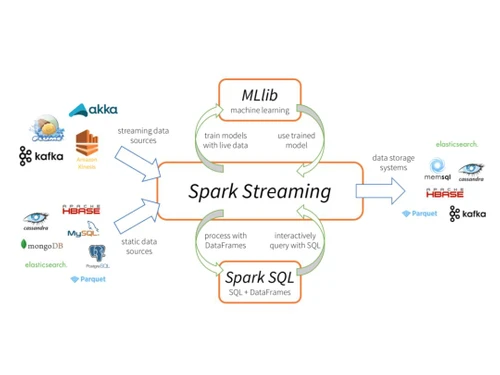
A standout feature of Apache Spark is its capacity for in-memory processing, which greatly accelerates data processing tasks compared to conventional methods that rely on disk-based operations. This advantage is particularly useful for executing iterative algorithms found in machine learning and graph computations. Pricing information for Apache Spark can be obtained upon request, with various factors influencing costs, including additional features, deployment types, and user counts.