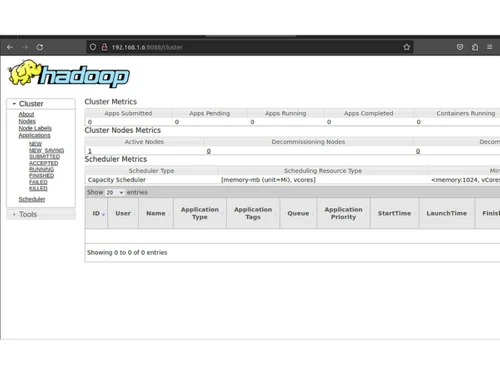
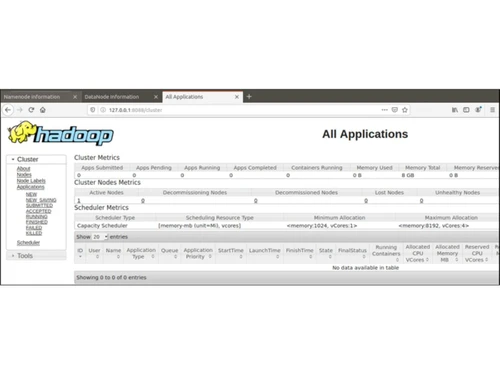
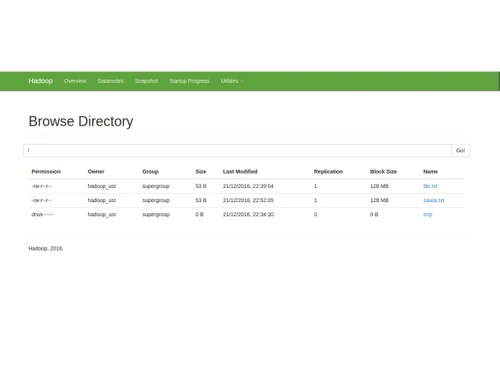
Designed for organizations dealing with extensive data sets, Apache Hadoop leverages the Hadoop Distributed File System (HDFS) to segment large data volumes into manageable units. This architecture distributes data across multiple machines, ensuring redundancy and system resilience even in the event of hardware failures.
For data processing, Hadoop employs MapReduce, which efficiently divides tasks into smaller components that can be executed simultaneously, streamlining the overall data handling process. Additionally, the YARN resource management framework plays a crucial role in overseeing resource allocation and job scheduling across the cluster, enhancing operational efficiency. This platform’s scalability allows users to begin with a handful of machines and scale up to thousands as their data requirements expand. Apache Hadoop is available for free from various sources, with pricing influenced by additional features, deployment choices, and user counts.