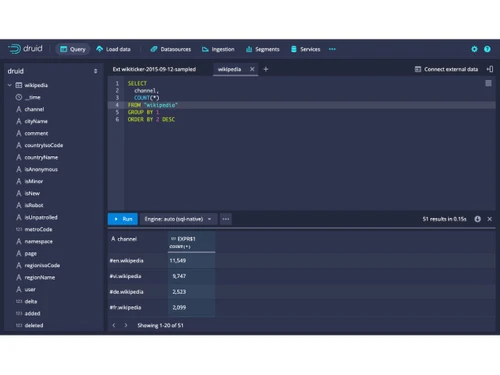
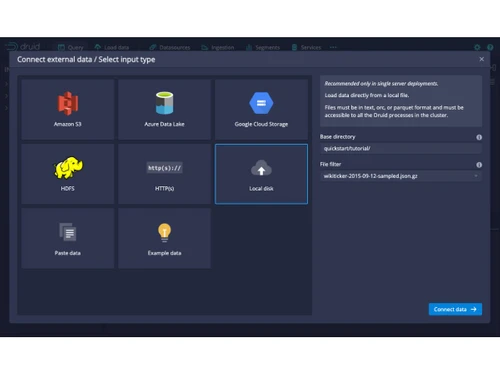
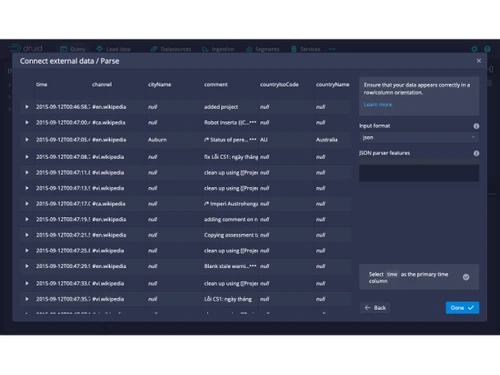
Apache Druid serves as an analytics database optimized for processing extensive volumes of both streaming and batch data, delivering quick query responses in under a second. Its distributed system architecture incorporates distinct nodes dedicated to data ingestion, storage, and querying, allowing for seamless scalability from individual servers to expansive clusters.
The platform’s data is organized in a column-oriented, time-indexed structure, facilitating effective filtering and aggregation, even across billions of data entries. Supporting real-time data ingestion from sources like Kafka or Kinesis, as well as batch processing, Druid ensures data is readily accessible for analysis. With standard SQL support, users can execute familiar queries for a variety of analytic tasks, including clickstream tracking, IoT data exploration, and marketing analysis. Apache Druid is available for free, with pricing influenced by deployment type and additional features.